(包学会)Kindle:如何无中生有创造目录!
2025-05-24 04:11:41
(包学会)Kindle:如何无中生有创造目录!
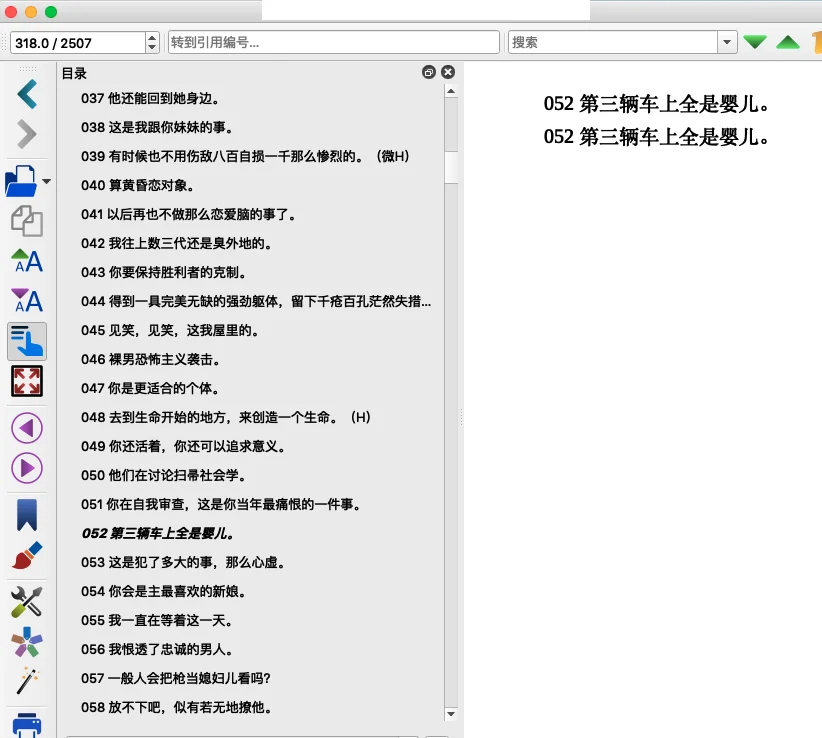



图一:直接用普通的正则式,因为识别不到章节,转出来的EPUB就是这样完全没有目录的。常见正则表达式://*[re:test(., "^\s*[第卷][0123456789一二三四五六七八九十零〇百千两]*[章回部节集卷].*", "i")]
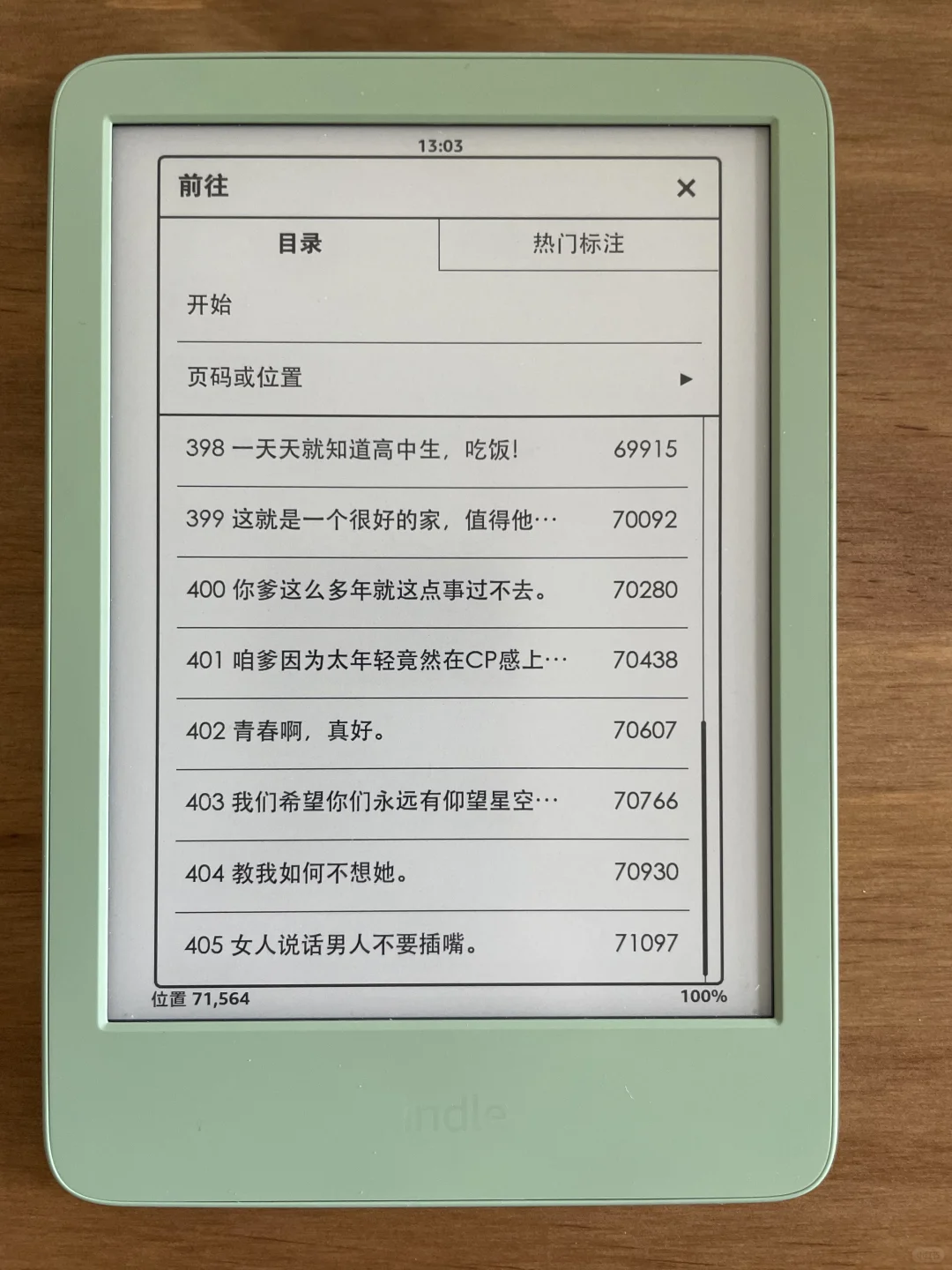
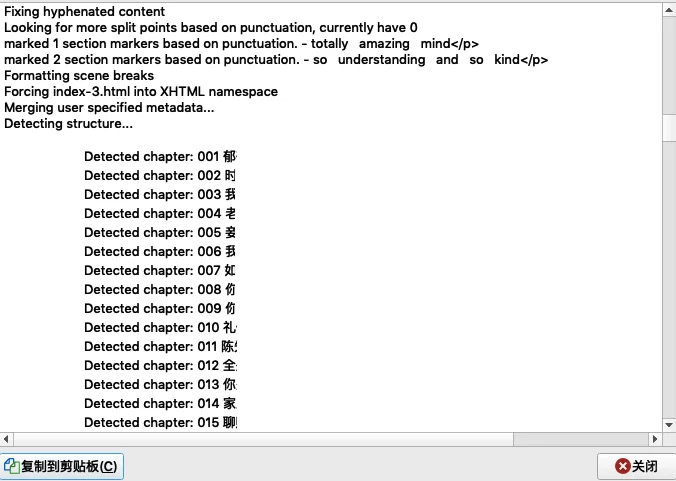
我教你怎么变成图二和图三
如果你的txt的格式是这样的:
001 开始
002 展开
003 结局
可以试着用这个://*[re:test(., "^\s*[0-9]+\s+.+", "i")]
现在难度增加,如果每章的数字都出现两次怎么办?
001 开始
001 开始
002 展开
002 展开
用这个://*[ re:test(., "^\s*[0-9]{3}\s+.+", "i") and not( preceding::*[re:test(., "^\s*[0-9]{3}\s+.+", "i")]/text() = ./text() ) ]
成功啦
#calibre #kindle #目录 #阅读器 #墨水屏