📚HTMLMyShelf:基于HTML的轻量级PDF书架
2025-05-02 13:34:33
📚HTMLMyShelf:基于HTML的轻量级PDF书架
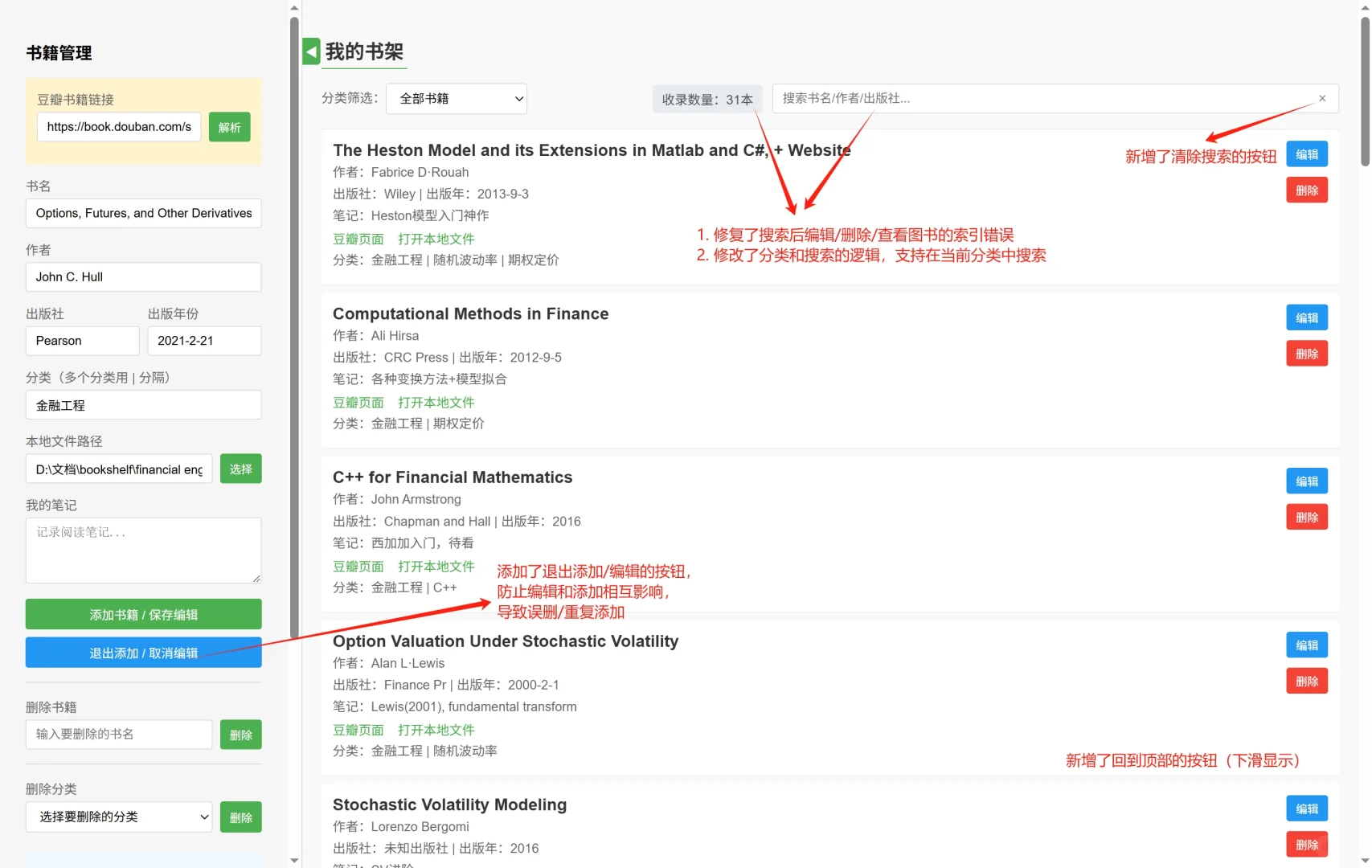
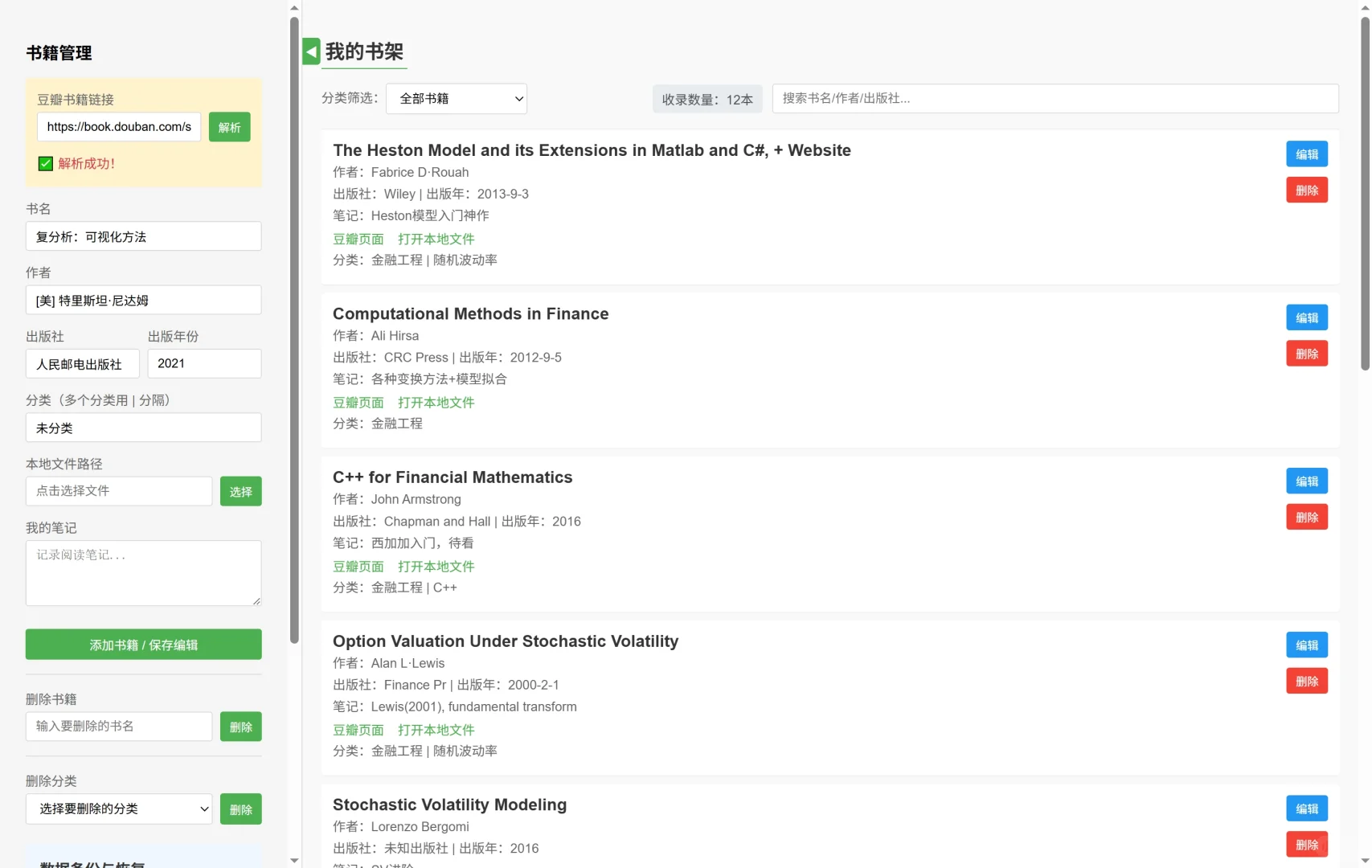
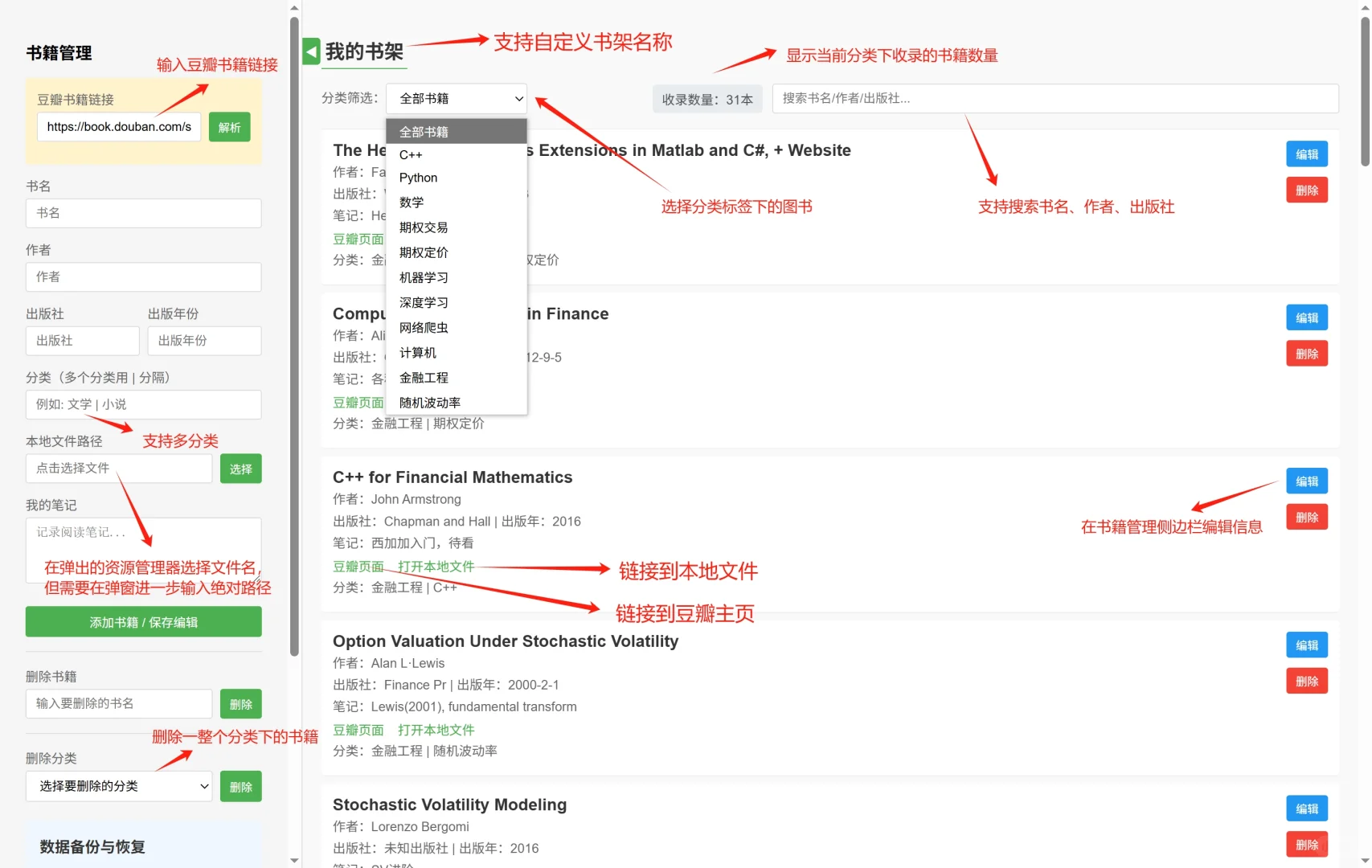
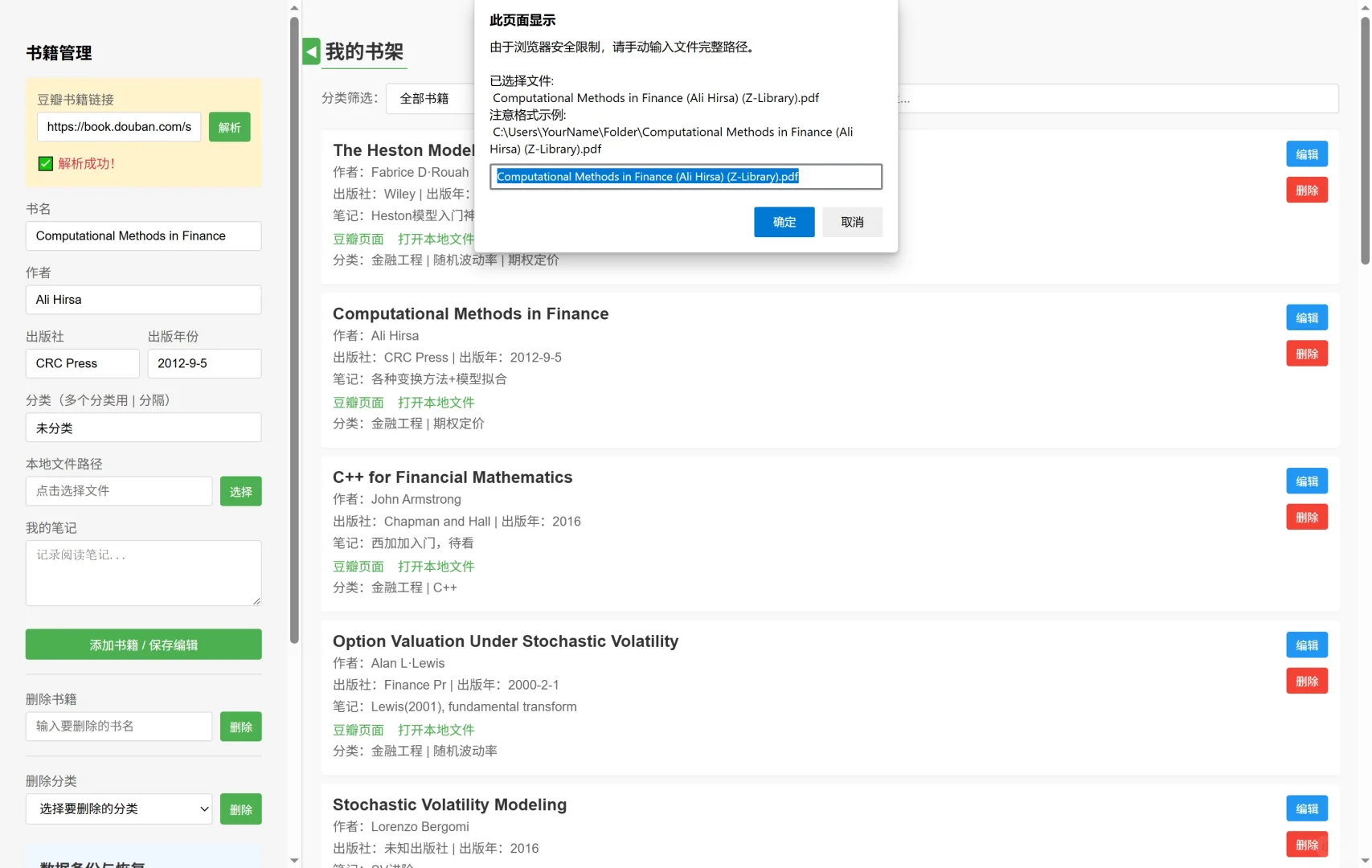
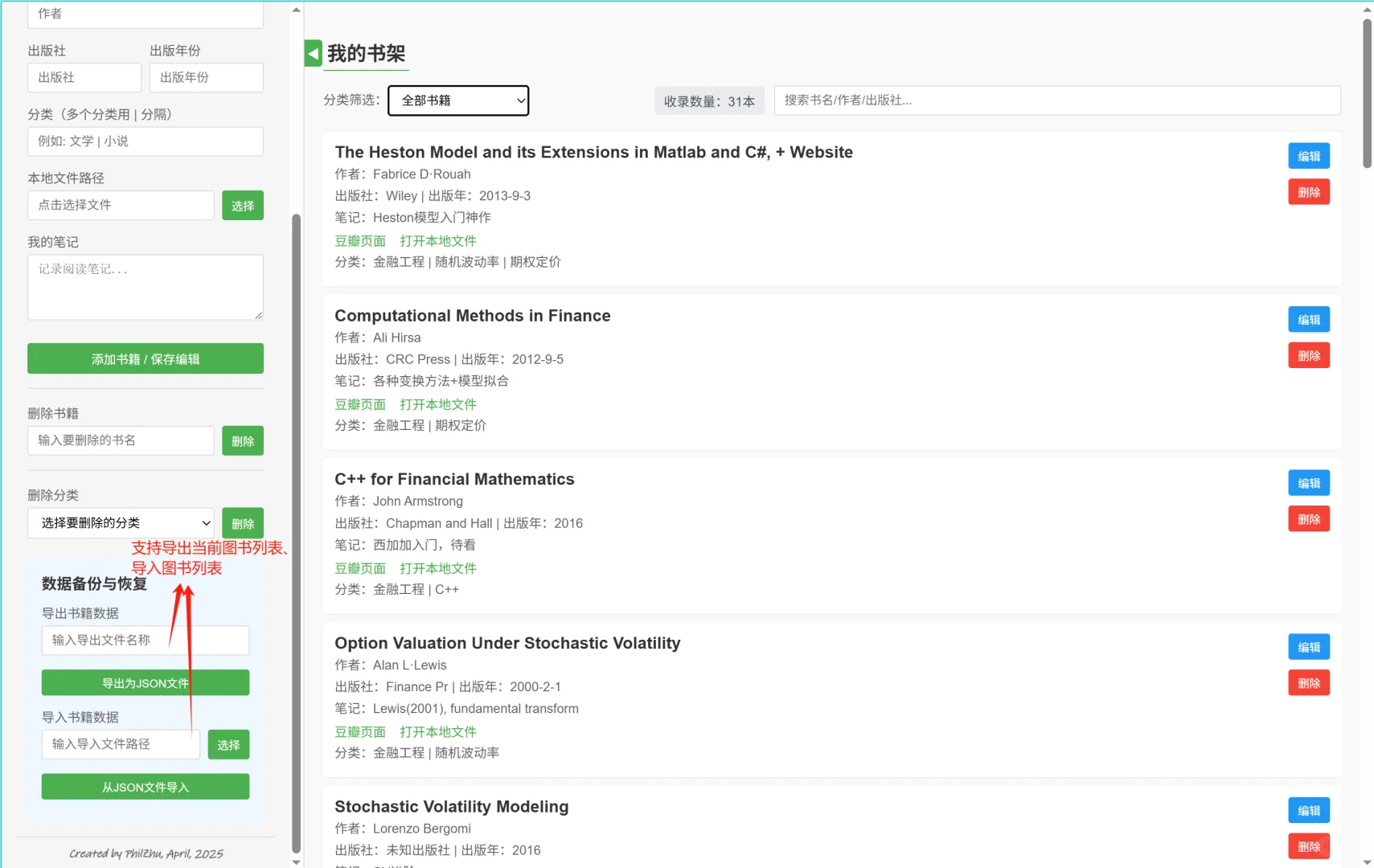

近日苦于临时要打开一本pdf书籍查阅资料,因为本人的pdf文件主要在浏览器打开,又不想每次都用zotero/calibre等文献管理软件,总感觉为了找个pdf打开这些软件太麻烦了,阅读文献倒是还可以接受。。。🤯\n于是想找一个能做到在浏览器里即查即看的轻量级工具,类似于专门针对pdf图书的资源管理器。但网上冲浪之后,发现似乎推荐的也都是类似于calibre的电子书管理软件。那么就自己动手写一个吧!🧑💻\n本来想用python造轮子🔨,但思来想去感觉还是开发一个纯基于HTML📄的前端文档最为方便。本人非科班出身,于是经过我向ds🤖老师的一番请教(拷打),最终得到了这样的一个页面(如图1)。\n目前大概支持的功能有(如图2):\n1. 豆瓣链接解析:输入豆瓣的书籍主页链接后,可以自动解析书籍的信息,输入链接例如https://book.douban.com/subject/35430545/;同时添加书籍后还可以链接到相应的豆瓣主页。\n2. 自定义图书信息:除了豆瓣的书籍外,对于一些“非标准化”格式的PDF文件,也可以自主输入相关的信息,比如出版年份之类的,还可以自己添加笔记、评论;同时还支持添加多个标签,用“|”分割即可。\n3. 支持链接本地文件:可以在“本地文件路径输入框”内键入图书PDF的路径,但注意弹出的资源管理器目前仅支持输入文件名,可以在弹出的提示框内输入完整路径(文件所在的绝对路径)(如图3)。\n4. 数据备份与恢复:因为输入的列表保存在浏览器的localStorage下方,所以可能电脑管家之类的软件在清楚浏览器数据的时候会误删已有的列表(还没以身试法过),并且数据无法直接跨浏览器、设备共享。因此可以在“数据备份与恢复”的选项栏下,输入自定义的导出文件名称,点击“导出为json文件”,将获得一个格式化的图书列表。在新的浏览器或新设备上再次打开这个文档时,导入相应的json文件即可。导入的数据将覆盖原有数据。(如图4)\n项目已经挂在了GitHub🐣上,\nhttps://github.com/phil-z1/HTMLMyShelf/tree/main,\n有需要的可以自行下载使用。喜欢的话可以帮我点个Star~~~⭐🌟✨\n有什么建议和需求可以在评论区或Github里提issue,本人会在能力范围内尽可能优化~🖱💻\n#PDF文件 #网页制作 #前端开发 #电子书管理 #文献查找 #电子书分享 #电子书下载 #研究生 #金融工程 #我爱学习